Поиск SharePoint 2013. Ранжирование на основе нейронных сетей
Поисковые системы в корпоративной среде с каждым годом становятся все более и более популярными. Связано это с накоплением большого объема информации практически никак не структурированного. Пользователи в такой ситуации не знают не только где искать необходимую им информацию, но и что именно искать (в каком виде информация хранится в корпоративной среде). И основным (порой единственным) инструментом для пользователей, применение которого способно привести к результату, становится поиск.
Поисковая система при обработке запроса должна выполнить следующие шаги:
- Поиск документов по наличию вхождений соответствующих запросу
- Ранжирование найденных документов
- Предоставление результатов поиска пользователю
С первым пунктом все предельно ясно. Единственное требование к поисковой системе здесь - умение "доставать" из документа информацию в пригодном для поиска виде. SharePoint 2013 справляется с этим очень хорошо.
Третий пункт в SharePoint 2013 реализован великолепно - информацию можно выводить практически в любом виде, используя Display template'ы.
Самое интересное - второй пункт. Здесь от поисковой системы требуется выбрать из документов, отобранных на предыдущем шаге (их может быть миллионы), только 10-20 тех, которые действительно представляют интерес для пользователя.
О том, как в SharePoint 2013 работает механизм ранжирования и пойдёт речь в этом посте. Я расскажу про линейные и двухслойные нейронные сети, используемые в модели ранжирования SharePoint 2013.
Модель ранжирования SharePoint 2013
При ранжирования все документы, отобранные на первом шаге поиска (кандидаты в результаты) проходят последовательно через две модели ранжирования, обеспечивающих расчет ранга. По умолчанию модель ранжирования в SharePoint 2013 состоит из двух моделей, первая из которых является линейной, вторая же представляет собой двухуровневую нейронную сетью. Выглядит все это примерно так:
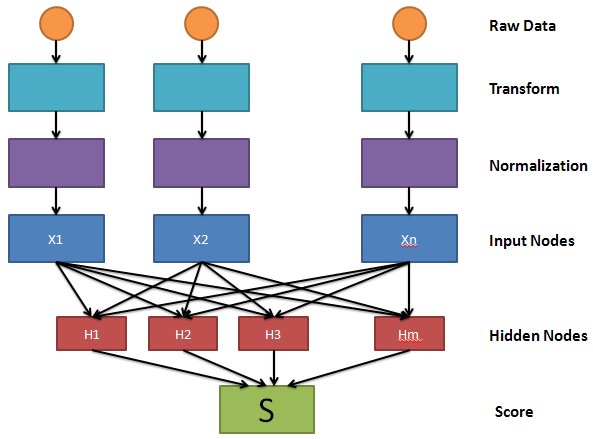
Каждый из кандидатов в результаты проходит через все шаги расчета ранга. В случае линейной модели количество скрытых нейронов в модели (H1,H2,H3,...Hm на рисунке) сокращено до одного. В остальном отличий нет.
Путь, который проходит поисковый запрос, чтобы превратиться в результаты поиска:

Модель ранжирования результатов поиска в SharePoint 2013, используемая по умолчанию (Default Search Model) выглядит примерно следующим образом (без описания фич трансформации):
<RankingModel2Stage name="RankingModelName" id="{GUID}" xmlns="urn:Microsoft.Search.Ranking.Model.2NN">
<RankingModel2NN id="{GUID}" precalcEnabled="1">
<HiddenNodes count="1">
<Thresholds>
<Threshold>0.000405176389917475</Threshold>
</Thresholds>
<Layer2Weights>
<Weight>1</Weight>
</Layer2Weights>
</HiddenNodes>
<RankingFeatures>
<!-- Features -->
</RankingFeatures>
</RankingModel2NN>
<RankingModel2NN id="{GUID}" maxStageWidCount="1000">
<HiddenNodes count="6">
<Thresholds>
<Threshold>-0.142921436240543</Threshold>
<Threshold>0.2484818168726</Threshold>
<Threshold>0.086614241829259</Threshold>
<Threshold>-0.0421435141549685</Threshold>
<Threshold>0.132033776270942</Threshold>
<Threshold>-0.10448525745989</Threshold>
</Thresholds>
<Layer2Weights>
<Weight>0.81767634141213</Weight>
<Weight>0.893481339647206</Weight>
<Weight>-0.492962956650105</Weight>
<Weight>-0.660686419330668</Weight>
<Weight>-0.648085912547058</Weight>
<Weight>-0.81325124029344</Weight>
</Layer2Weights>
</HiddenNodes>
<RankingFeatures>
<!-- Features -->
</RankingFeatures>
</RankingModel2NN>
</RankingModel2Stage>
Здесь описаны две модели (RankingModel2NN). Основное отличие их друг от друга - кол-во скрытых нейронов (HiddenNodes). При расчете ранга необходимо пройти через все скрытые нейроны как в первой так и во второй моделях (последовательно).
У каждого из скрытых нейронов указывается его вес (Layer2Weights - Weight) и пороговое значение (Thresholds - Threshold), достигнув которого сигнал передается далее.
Весы и пороговые значения
Layer2Weight - вес (множитель) значения, полученного на выходе из скрытых нейронов. Вес значений, поступающих на вход скрытых нейронов указывается в фичах трансформации (см. ниже пункт Transform). Таким образом в поисковой системе SharePoint 2013 достигается возможность "обучать" поиск, изменяя веса на одном из уровней нейронной сети либо пороговые значения скрытых нейронов.
Расчет ранга
Вкратце о каждом из этапом расчета на примере линейной модели (с одним скрытым нейроном).
Raw data
На этом шаге в модель поступают данные, пригодные для расчета ранга. Данные приходят в различном формате (текст, числа, булевы значения и прочее). Никаких преобразований не происходит.
Transform
На этом шаге начинается расчет ранга для документа. Для этого используются фичи преобразования, описанные в модели ранжирования. Более подробно я напишу в следующих постах о тюнинге поиска в SharePoint 2013. А пока для примера возьмём одну из них - преобразование на основе глубины страницы (UrlDepth):
<RankingModel2Stage xmlns="urn:Microsoft.Search.Ranking.Model.2NN">
<RankingModel2NN id="C238DBDE-33F1-4F2E-B0EB-D1FA2A147CBE" precalcEnabled="1">
<RankingFeatures>
<Static name="UrlDepth" default="3" propertyName="UrlDepth">
<Transform type="Rational" k="13.207950448860517" />
<Layer1Weights>
<Weight>-0.361451533701794</Weight>
</Layer1Weights>
</Static>
</RankingFeatures>
</RankingModel2NN>
</RankingModel2Stage>
В 5-й строке указан коэффициент (k) трансформации и её тип (Rational). Тип трансформации определят формулу для расчета ранга. В MSDN'е есть таблица с описанием всех возможных типов и соответствующих им формул:
)
В нашем случае используется Rational, т.е. формула имеет следующий вид:
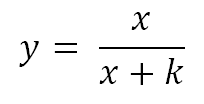
При указанном значении коэффициента k (13.207950448860517) зависимость значения трансформации от глубины вложения выглядит примерно следующим образом:
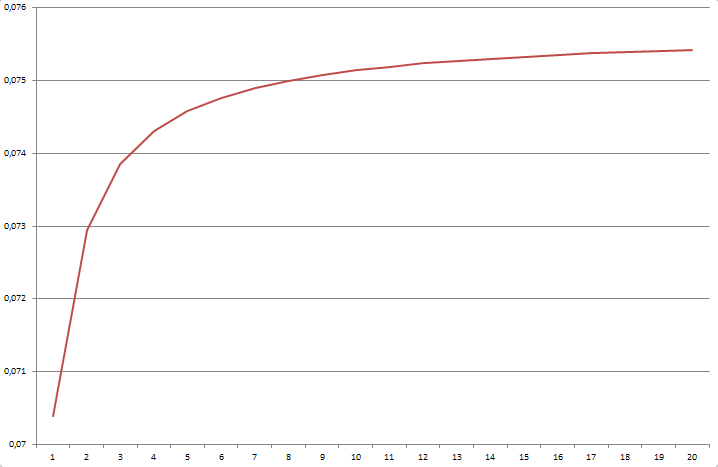
На графике видно, что глубина вложения документа (кол-во "/" в адресе) практически не оказывает значения на ранг при больших величинах (более 7).
Normalization
После трансформации происходит нормализация значений, полученных на выходе (не всегда, только при наличии ограничений). Ничего особенного.
Input nodes
Задача поиска на этом шаге - параллельный запуск преобразований в Hidden nodes. Значение на выходе из каждого входного нейрона (Input Nodes) подается на вход всем скрытым нейронам (HiddenNodes).
Hidden nodes
Последний этап расчета ранга документа, позволяющий воздействовать на итоговое значение. На этом этапе влияние на ранг оказывает значение веса (Layer1Weight и Layer2Weight). При этом Layer1Weight используется в качестве множителя для значения на входе в скрытый нейрон, Layer2Weight - множитель для значения на выходе перед расчетом итогового значения.
Результат расчета ранга
На последнем этапе происходит суммирование значений, полученных на выходе из скрытых нейронов, с учетом их веса (Layer2Weight). Эти значения суммируются, результатом чего я является ранг (Score).
Напоследок пример лога ранжирования поиска (маленький кусочек):
<rank_log corr_id="{GUID}" instance_id="{INSTANCE_ID}" id="{GUID}" version="15.0.0000.1000">
<query tree='{TREE}' properties='{PROPERTIES}'/>
<stage id="{GUID}" stage_rank_interval="[-2.99419,36.0186]" rank_after="1.4263" rank="1.4263" type="linear">
<!-- -->
</stage>
<stage id="{GUID}" stage_rank_interval="[-4.32614,4.32614]" rank_after="41.7432" rank="1.39846" type="neural_net">
<!-- -->
</stage>
</rank_log>
Где,
- stage_rank_interval - интервал ранга, [минимум, максимум]
- rank_after - значение ранга до прохода
- rank - значение ранга на выходе
- type - тип модели ранжирования
Итоговым значением ранга будет значение rank_after из второй (последней) стадии ранжирования (41.7432). Это значение получается путем вычитания из максимального значения первой стадии (36.0186) минимальное значение второй стадии (-4.32614). Нейронная сеть используется для корректировки значений, рассчитанных на первой (линейной) стадии. Поиск лучших из лучших.
Первая модель используется для расчета ранга, все последующие - лишь корректируют ранг, рассчитанный на предыдущих шагах.
Продолжение следует.
P.S.
Кому интересен поиск в SharePoint 2013 и его новые возможности - регистрируйтесь на трансляцию октябрьской встречи RuSUG 17 октября. Будет интересно.







