Поиск для сайта на базе SharePoint 2013. Часть 1: robots.txt, sitemap.xml и другие особенности
Часть 1: robots.txt, sitemap.xml и другие особенности
Часть 2. Адаптация сайта
Поиск в SharePoint 2013 получился у Microsoft более чем хорош. Благодаря этому SharePoint 2013 может рассматриваться как платформа, которая способна обеспечить поиск не только в корпоративной среде, но и на просторах интернета - для веб-сайта (одного или нескольких).
В сегодняшнем посте я покажу на примере как SharePoint 2013 индексирует содержимое веб-сайтов и его реакцию (или отсутствие таковой) на файлы robots.txt, sitemap.xml. Заодно про механизм запрета индексирования части содержимого веб-страницы и об одном мифе, с ним связанного.
Подопытный
Для демонстрации того, как поисковая система SharePoint 2013 работает с внешними веб-сайтами, я создал простой сайт search.vitalyzhukov.ru (он работает, кому интересно - можете посмотреть). Страницы на сайте самые обычные - просто HTML и ничего больше. Карта сайта следующая:
- robots.txt
- sitemap.xml
- /default.html
- /page1.html
- /page2.html
- /page3.html
- /sub1/default.html
- /sub1/page1.html
- /sub1/sub2/default.html
Настраиваем профилирование краулера и начинаем эксперимент.
Запрет индексирования части документа
Для того, чтобы запретить SharePoint'у индексировать часть страницы, надо пометить контейнер, его содержащий, классом noindex (class="noindex"). В одном из блогов, посвященных SharePoint, говорилось, что этот механизм не работает с вложенными контейнерами и каждый из них надо явно помечать классов noindex, иначе его содержимое будет проиндексировано. Для проверки этого мифа все ссылки на страницы /page2.html и page3.html на тестовом сайте имеют следующий вид:
<div class="noindex">
<a href="/page2.html">page2</a>
<div>
<a href="/page3.html">page3</a>
</div>
</div>
Если описанный миф подтвердится, то страница page3.html будет проиндексирована. Запускаем обход содержимого и смотрим на результаты в fiddler'е:

Миф разрушен. Все содержимое контейнеров, значение атрибута class которых содержит noindex не индексируется поисковиком SharePoint 2013.
robots.txt
На изображении выше видно, что первое, что делает краулер - пытается найти файл robots.txt в корне сайта. Содержимое моего файла robots.txt следующее:
User-agent: *
Disallow: /sub1/sub2
Краулер не проиндексировал страницы, расположенные по адресу /sub1/sub2, т.к. это было явно запрещено в файле robots.txt.
Sitemap.xml
Для того, чтобы краулер SharePoint учитывал содержимое файла sitemap.xml, ссылку на него надо явно указывать в файле robots.txt. Добавим ссылку на sitemap.xml и выполним ещё один обход содержимого. Новая строка в robots.txt:
User-agent: *
Disallow: /sub1/sub2
Sitemap: http://search.vitalyzhukov.ru/sitemap.xml
Результат в fiddler'е:
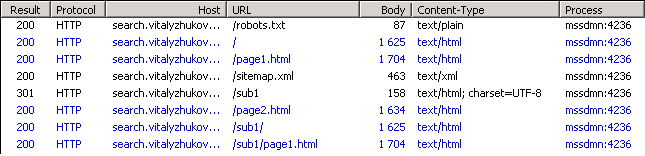
Была также проиндексирована страница /sub1/page1.html. Никакие другие страницы демо-сайта не содержат ссылок на неё. Информация о ней содержится только в файле sitemap.xml:
<urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9">
<url>
<loc>http://search.vitalyzhukov.ru</loc>
<priority>1</priority>
</url>
<url>
<loc>http://search.vitalyzhukov.ru/sub1/page1.html</loc>
<priority>0.5</priority>
</url>
</urlset>
SharePoint 2013 индексирует страницы, информация о которых содержится в файле sitemap.xml.
rel="nofollow"
Ещё одна особенность поисковика SharePoint 2013. Ссылки имеющие атрибут rel="nofollow" будут проиндексированы. На демо-сайте это страница /nofollow.html, ссылка на которую есть в /default.html:
<a href="/nofollow.html" rel="nofollow">nofollow</a>
Теперь ясно как SharePoint индексирует веб-сайты. В следующей части я расскажу как адаптировать веб-сайт для индексации его силами SharePoint 2013.







