Поиск SharePoint 2013. Кастомная модель ранжирования
Небольшой пример использования кастомной модели ранжирования при создание решений, основанных на поиске SharePoint 2013.
В этом примере я покажу как создать поиск сотрудников, информация о которых хранится в списке. При этом будет создана простая кастомная модель ранжирования, обеспечивающая необходимое ранжирование.
Список
Список будет предельно простым, содержащим следующие поля:
- FullName (Title) - полное имя сотрудника. Конкатенация значений полей Surname, Name;
- Surname - фамилия сотрудника;
- Name - имя сотрудника;
- Position - должность;
- Grade - уровень грейда (целое число от 0 до 5);
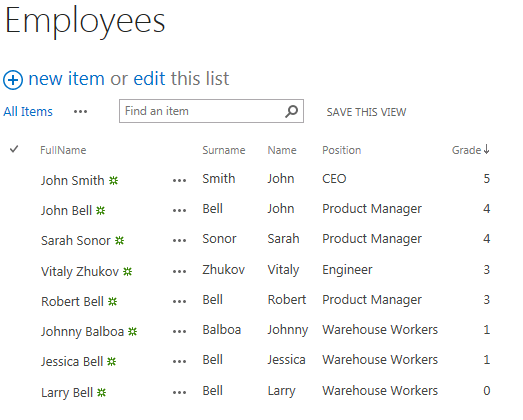
Тестовые данные:
Требования к ранжированию
Модель ранжирования должна следовать следующим приоритетам при расчете ранга:
- выводить только сотрудников и никакой больше информации;
- вхождения, найденные в поле Surname являются наиболее важными;
- вхождения, найденные в поле Position являются вторыми по важности;
- выводить выше остальных результатов, равных по количеству вхождений, сотрудников с наиболее высоким грейдом.
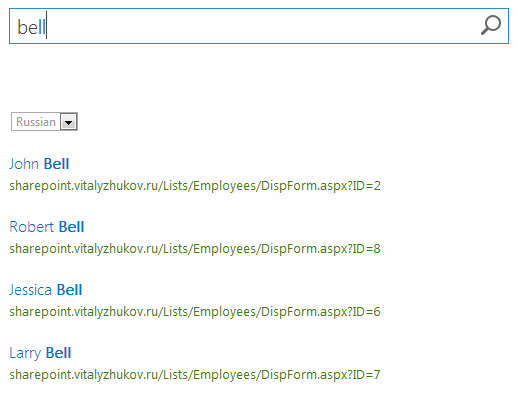
При поиске "bell" должны быть выведены сотрудники по фамилии Bell в слдующем порядке:
- John Bell (grade=4)
- Robert Bell (grade=4)
- Jessica Bell (grade=1)
- Larry Bell (grade=0)
Контрольная группа
Перед тем как приступить посмотрим, как работает стандартная модель ранжирования:
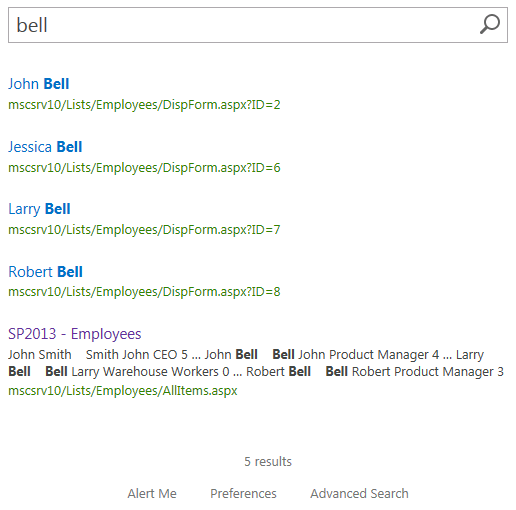
В результатах поиска кладовщик оказался выше своего руководства, что неприемлемо. Конечно со временем, когда пользователи будут переходить по ссылкам в результатах поиска (игнорируя кладовщика), модель ранжирования "обучится" и опустит вниз результаты поиска, переходы по которым не осуществляются. Но бизнес не ждет.
Модель ранжирования
Для реализации нам понадобится кастомная модель ранжирования. В нашем случае нет необходимости в нейронных сетях, будет достаточно простой линейной модели. Болванка для будущей модели:
<RankingModel2Stage name="Employee OneStage Linear Model" description="" id="{GUID}" xmlns="urn:Microsoft.Search.Ranking.Model.2NN">
<RankingModel2NN id="{GUID}" precalcEnabled="1">
<HiddenNodes count="1">
<Thresholds>
<Threshold>0.000405176389917475</Threshold>
</Thresholds>
<Layer2Weights>
<Weight>1</Weight>
</Layer2Weights>
</HiddenNodes>
<RankingFeatures>
<!-- Features -->
</RankingFeatures>
</RankingModel2NN>
</RankingModel2Stage>
Вес и пороговое значение для скрытого нейрона в нашем случае значения не имеют. Главное, что вес не был нулевым, иначе ранг будет нулевой и пороговое значение нейрона должно быть достаточно малым.
Стандартную фичу поиска вхождений в тексте (BM25Main) настраиваем на поиск только в полях Surname, Name, Position. Остальные поля нас не интересуют. Веса расставляем в соответствии с требованиями:
<RankingModel2Stage name="Employee Search Model" description="" id="{GUID}" xmlns="urn:Microsoft.Search.Ranking.Model.2NN">
<RankingModel2NN id="{GUID}" precalcEnabled="1">
<HiddenNodes count="1">
<Thresholds>
<Threshold>0.000405176389917475</Threshold>
</Thresholds>
<Layer2Weights>
<Weight>1</Weight>
</Layer2Weights>
</HiddenNodes>
<RankingFeatures>
<!-- Features -->
</RankingFeatures>
</RankingModel2NN>
</RankingModel2Stage>
Требования выводить сначала сотрудников с более высоким грейдом нам поможет решить фича BucketedStatic. С помощью этой фичи можно изменять значения ранга в зависимости от значения свойства (что-то вроде оператора switch в C#):
<BucketedStatic name="EmployeeGrade" default="0" propertyName="EmployeeGrade">
<Bucket name="0" value="0"><HiddenNodesAdds><Add>0</Add></HiddenNodesAdds></Bucket>
<Bucket name="1" value="1"><HiddenNodesAdds><Add>1</Add></HiddenNodesAdds></Bucket>
<Bucket name="2" value="2"><HiddenNodesAdds><Add>2</Add></HiddenNodesAdds></Bucket>
<Bucket name="3" value="3"><HiddenNodesAdds><Add>3</Add></HiddenNodesAdds></Bucket>
<Bucket name="4" value="4"><HiddenNodesAdds><Add>4</Add></HiddenNodesAdds></Bucket>
<Bucket name="5" value="5"><HiddenNodesAdds><Add>5</Add></HiddenNodesAdds></Bucket>
</BucketedStatic>
Новая модель готова. Для начала регистрируем её с помощью PowerShell скрипта из MSDN:
$myRankingModel = Get-Content .\myrm.xml
$myRankingModel = [String]$myRankingModel
$ssa = Get-SPEnterpriseSearchServiceApplication
$owner = Get-SPenterpriseSearchOwner -Level ssa
$newrm = New-SPEnterpriseSearchRankingModel -SearchApplication $ssa -Owner $owner -RankingModelXML $myRankingModel</pre>
Модель в SharePoint зарегистрирована, можно приступать к настройке интерфейса.
Интерфейс пользователя
Поиск сотрудников будет реализован на отдельной странице. Добавляем на неё веб-части Search Box и Search Results. В свойствах веб-части Search Results открываем диалог для настройки запроса:
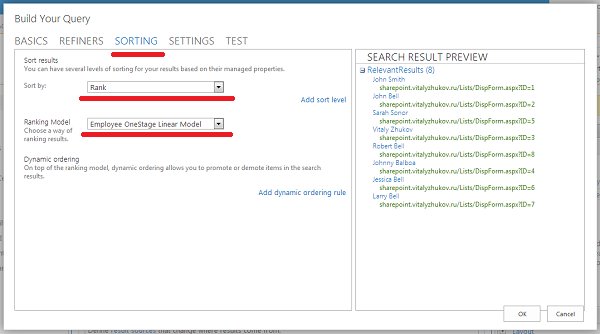
Для выбора модели ранжирования переходим на вкладку Sorting. Указываем поле сортировки (Rank) и модель ранжирования (Employee OneStage Linear Model):
Чтобы в результатах были только сотрудники можно добавить фильтр к запросу по типу содержимого. Для этого на вкладке Basics к тексту запроса (Query text) дописываем соответствующий фильтр:
ContentType=CustomEmployee
Все готово. Сохраняем изменения и проверяем результат.
Результат
При запросе "bell":
При запросе "john*":
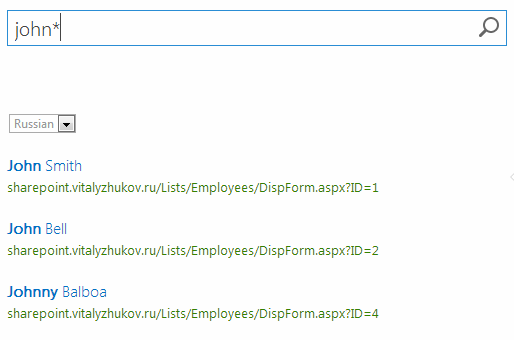
Все работает отлично. Можно изменить веса полей Surname и Name, чтобы совпадение найденное в фамилии было более важным, чем совпадение в имени. В этом случае Ивановы будут выше Иванов в результатах поиска.
Простое решение, основанное на поиске SharePoint 2013, реализация которого укладывается в 2 часа. И никакого кодинга.
Напоследок модель ранжирования целиком:
<RankingModel2Stage name="Employee OneStage Linear Model"
description=""
id="825f23c2-f06f-49a0-8b9f-2d2d754bf459"
xmlns="urn:Microsoft.Search.Ranking.Model.2NN">
<RankingModel2NN id="f7c4bce6-7f55-4b79-97e8-cf79a795a12b"
precalcEnabled="0">
<HiddenNodes count="1">
<Thresholds>
<Threshold>0.000405176389917475</Threshold>
</Thresholds>
<Layer2Weights>
<Weight>1</Weight>
</Layer2Weights>
</HiddenNodes>
<RankingFeatures>
<!-- Поиск в содержимом -->
<BM25Main name="ContentRank" k1="1">
<Layer1Weights>
<Weight>0.267001870579081</Weight>
</Layer1Weights>
<!-- Свойства и их веса -->
<Properties>
<Property name="EmployeeSurname" w="10" b="0.5" propertyName="EmployeeSurname" />
<Property name="EmployeeName" w="10" b="0.5" propertyName="EmployeeName" />
<Property name="EmployeePosition" w="5" b="0.5" propertyName="EmployeePosition" />
</Properties>
</BM25Main>
<!-- Ранг на основе значения поля -->
<BucketedStatic name="EmployeeGrade" default="0" propertyName="EmployeeGrade">
<Bucket name="0" value="0"><HiddenNodesAdds><Add>0</Add></HiddenNodesAdds></Bucket>
<Bucket name="1" value="1"><HiddenNodesAdds><Add>1</Add></HiddenNodesAdds></Bucket>
<Bucket name="2" value="2"><HiddenNodesAdds><Add>2</Add></HiddenNodesAdds></Bucket>
<Bucket name="3" value="3"><HiddenNodesAdds><Add>3</Add></HiddenNodesAdds></Bucket>
<Bucket name="4" value="4"><HiddenNodesAdds><Add>4</Add></HiddenNodesAdds></Bucket>
<Bucket name="5" value="5"><HiddenNodesAdds><Add>5</Add></HiddenNodesAdds></Bucket>
</BucketedStatic>
</RankingFeatures>
</RankingModel2NN>
</RankingModel2Stage>
P.S.
Кому интересен поиск в SharePoint 2013 и его новые возможности - регистрируйтесь на трансляцию октябрьской встречи RuSUG 17 октября. Будет интересно.







